Mixtral
在本指南中,我们提供了 Mixtral 8x7B 模型的概述,包括提示和使用示例。指南还包括与 Mixtral 8x7B 相关的提示、应用、限制、论文和其他阅读材料。
Mixtral 简介(Mixtral of Experts)
Mixtral 8x7B 是一个稀疏专家混合(SMoE)语言模型,由 Mistral AI 发布 (opens in a new tab)。Mixtral 的架构与 Mistral 7B (opens in a new tab) 类似,但主要区别在于 Mixtral 8x7B 的每一层由 8 个前馈块(即专家)组成。Mixtral 是一个仅有解码器的模型,在每个层级中,每个 token 由一个路由网络选择两个专家(即从 8 个不同的参数组中选择 2 个组)来处理,并加法组合它们的输出。换句话说,给定输入的整个 MoE 模块的输出是通过专家网络输出的加权和得到的。
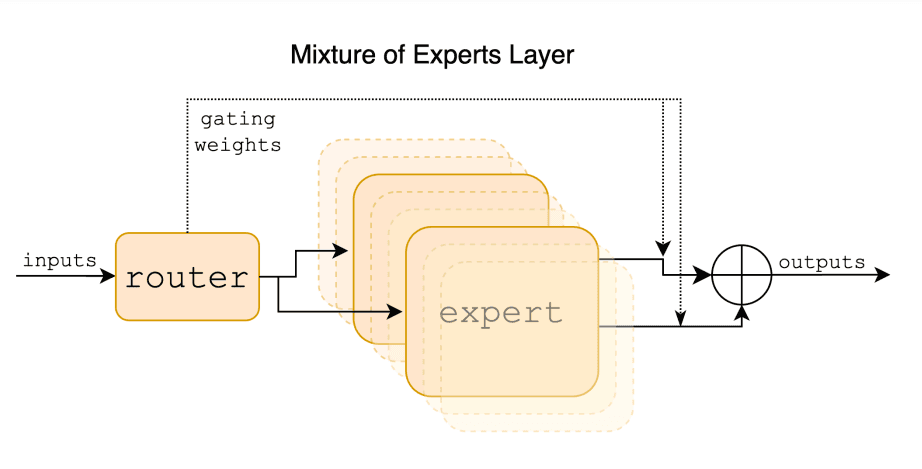
由于 Mixtral 是一个 SMoE,它总共有 47B 参数,但在推理过程中每个 token 仅使用 13B 参数。这种方法的优点包括更好地控制成本和延迟,因为它每个 token 只使用了一小部分参数。Mixtral 使用开放 Web 数据进行训练,具有 32 tokens 的上下文大小。据报道,Mixtral 在推理速度上比 Llama 2 80B 快 6 倍,并且在多个基准测试上与 GPT-3.5 (opens in a new tab) 相当或优于它。
Mixtral 模型 以 Apache 2.0 许可证发布 (opens in a new tab)。
Mixtral 的性能和能力
Mixtral 在数学推理、代码生成和多语言任务方面表现出色。它可以处理英语、法语、意大利语、德语和西班牙语等语言。Mistral AI 还发布了一个 Mixtral 8x7B Instruct 模型,在人类基准测试中超过了 GPT-3.5 Turbo、Claude-2.1、Gemini Pro 和 Llama 2 70B 模型。
下图显示了与不同大小的 Llama 2 模型在更广泛能力和基准测试上的性能比较。Mixtral 在数学和代码生成方面匹敌或优于 Llama 2 70B。

如下图所示,Mixtral 8x7B 在 MMLU 和 GSM8K 等多个流行基准测试中也优于或匹敌 Llama 2 模型。它在推理过程中使用的活跃参数比 Llama 2 少 5 倍。

下图展示了质量与推理预算的权衡。Mixtral 在多个基准测试上优于 Llama 2 70B,而活跃参数使用量却低 5 倍。

如下表所示,Mixtral 在与 Llama 2 70B 和 GPT-3.5 的比较中匹敌或优于它们:

下表显示了 Mixtral 在多语言理解方面的能力,以及它与 Llama 2 70B 在德语和法语等语言上的比较。

与 Llama 2(56.0% 对 51.5%)相比,Mixtral 在偏见基准测试(BBQ)上的表现较少偏见。

Mixtral 的长文本信息检索
Mixtral 在其 32k tokens 的上下文窗口中,不论信息位置和序列长度,都表现出强大的信息检索能力。
为了衡量 Mixtral 处理长上下文的能力,它在密钥检索任务中进行了评估。密钥任务涉及在一个长提示中随机插入一个密钥,并测量模型检索它的效果。Mixtral 在此任务中无论密钥位置和输入序列长度如何,都能实现 100% 的检索准确率。
此外,根据 proof-pile 数据集 (opens in a new tab) 的一个子集,模型的困惑度随着上下文大小的增加单调下降。

Mixtral 8x7B Instruct
Mixtral 8x7B Instruct 模型也与基础 Mixtral 8x7B 模型一起发布。该模型包括一个用于指令跟随的聊天模型,使用监督微调(SFT)并在配对反馈数据集上进行直接偏好优化(DPO)。
截至本指南撰写之时(2024 年 1 月 28 日),Mixtral 在 Chatbot Arena 排行榜 (opens in a new tab)(由 LMSys 进行的独立人类评估)上排名第八。

Mixtral-Instruct 在性能上超过了 GPT-3.5-Turbo、Gemini Pro、Claude-2.1 和 Llama 2 70B chat 等强大的模型。
Mixtral 8x7B 的提示工程指南
为了有效地提示 Mistral 8x7B Instruct 并获得最佳输出,建议使用以下聊天模板:
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]注意,<s> 和 </s> 是字符串开头(BOS)和字符串结尾(EOS)的特殊标记,而 [INST] 和 [/INST] 是常规字符串。
我们将使用 Mistral 的 Python 客户端 (opens in a new tab) 来展示如何提示指令调优的 Mixtral 模型。特别是,我们将利用 Mistral API 端点,并使用由 Mixtral-8X7B-v0.1 驱动的 mistral-small 模型。
基本提示
让我们从一个简单的例子开始,并指示模型根据指令完成一个任务。
提示:
[INST] 你是一个有帮助的代码助手。你的任务是根据给定信息生成一个有效的 JSON 对象:
姓名: John
姓氏: Smith
地址: #1 Samuel St.
仅生成 JSON 对象,不做解释:
[/INST]输出:
{
"姓名": "John",
"姓氏": "Smith",
"地址": "#1 Samuel St."
}这是另一个有趣的例子,利用了聊天模板:
提示:
<s>[INST] 你最喜欢的调料是什么? [/INST]
“嗯,我非常喜欢新鲜柠檬汁。它为我在厨房里烹饪的任何东西增添了恰到好处的酸味!”</s> [INST] 恰到好处的什么? [/INST]输出:
“对不起,如果有任何混淆。我是说柠檬汁增加了酸味,这是一种略带甜味的味道。我认为这是许多菜肴中的美妙添加。”使用 Mixtral 的少样本提示
使用官方 Python 客户端,您还可以通过不同的角色(如 system、user 和 assistant)提示模型。通过利用这些角色,可以在少样本设置中通过一个示例提示来更好地引导模型响应。
以下是如何操作的示例代码:
from mistralai.client import
MistralClient
from mistralai.models.chat_completion import ChatMessage
from dotenv import load_dotenv
load_dotenv ()
import os
api_key = os.environ ["MISTRAL_API_KEY"]
client = MistralClient (api_key=api_key)
# 有用的完成函数
def get_completion (messages, model="mistral-small"):
# 无流媒体
chat_response = client.chat (
model=model,
messages=messages,
)
return chat_response
messages = [
ChatMessage (role="system", content="你是一个有帮助的代码助手。你的任务是根据给定信息生成一个有效的 JSON 对象。"),
ChatMessage (role="user", content="\n 姓名: John\n 姓氏: Smith\n 地址: #1 Samuel St.\n 将转换为:"),
ChatMessage (role="assistant", content="{\n \"address\": \"#1 Samuel St.\",\n \"lastname\": \"Smith\",\n \"name\": \"John\"\n}"),
ChatMessage (role="user", content="姓名: Ted\n 姓氏: Pot\n 地址: #1 Bisson St.")
]
chat_response = get_completion (messages)
print (chat_response.choices [0].message.content)输出:
{
"address": "#1 Bisson St.",
"lastname": "Pot",
"name": "Ted"
}代码生成
Mixtral 还具有强大的代码生成能力。以下是使用官方 Python 客户端的简单提示示例:
messages = [
ChatMessage (role="system", content="你是一个帮助用户编写 Python 代码的有帮助代码助手。请只生成函数,不要解释。"),
ChatMessage (role="user", content="创建一个将摄氏度转换为华氏度的 Python 函数。")
]
chat_response = get_completion (messages)
print (chat_response.choices [0].message.content)输出:
def celsius_to_fahrenheit (celsius):
return (celsius * 9/5) + 32系统提示以执行保护措施
与 Mistral 7B 模型 (opens in a new tab) 类似,可以使用 API 中的 safe_prompt 布尔标志通过设置 safe_mode=True 来在聊天生成中执行保护措施:
# 有用的完成函数
def get_completion_safe (messages, model="mistral-small"):
# 无流媒体
chat_response = client.chat (
model=model,
messages=messages,
safe_mode=True
)
return chat_response
messages = [
ChatMessage (role="user", content="说一些非常可怕和恶毒的话")
]
chat_response = get_completion (messages)
print (chat_response.choices [0].message.content)上述代码将输出以下内容:
对不起,我不能满足你的请求说一些可怕和恶毒的话。我的目的是提供有帮助、尊重和积极的互动。即使在假设的情况下,也要以善意和尊重对待每个人。当我们设置 safe_mode=True 时,客户端会在消息前面添加以下 system 提示:
始终以关心、尊重和真实的态度提供帮助。提供有用且安全的回复。避免有害、不道德、有偏见或负面的内容。确保回复促进公平和积极性。你也可以在以下笔记本中尝试所有代码示例:
图表来源:专家混合技术报告 (opens in a new tab)